Health Information Exchange

Introduction
When cancer care teams utilize electronic health records, there is potential to collect real world data that supports daily patient coordination and management regardless of where cancer treatment occurs. This data can also serve as evidence for researchers looking to improve patient health outcomes. However, unless the data are represented in a structured format using common terms, patients, providers, and researchers alike struggle to share and use this information. Cancer data needs to be represented in a structured way with common vocabulary across organizations, to unlock its value for patient care and research.
mCODE® (minimal Common Oncology Data Elements) is a standard that addresses this need and is being adopted now. In 2018, the American Society of Clinical Oncology (ASCO) and the MITRE Corporation convened a workgroup of oncologists, informaticians, experts in terminologies and standards, and researchers to create the standard. mCODE is a consensus based, open data exchange standard that defines a core set of common data elements for cancer. By serving as a common language for cancer data across the health ecosystem, mCODE makes patient cancer data standardized, computable, and accessible. Thus, mCODE provides a standard language that can drive insights on a large scale. Based on FHIR® (Fast Healthcare Interoperability Resources), a healthcare data exchange standard increasingly supported by industry and government agencies internationally, mCODE is gaining traction among healthcare organizations and digital health industry leaders.
Increased adoption increases the value of mCODE-based data. The growing adoption and implementation of mCODE is crucial for unlocking the full potential of real-world cancer patient data. Implementing an evolving standard like mCODE can be difficult. The level of experience utilizing new specifications and data standards varies across businesses, business leaders, clinical informaticists, FHIR engineers, and other operational support. This article is intended to help organizations navigate the mCODE implementation. It presents background information and describes a mix of clinical and technical key takeaways, challenges, and future considerations for those who have already adopted or are in the process of implementing mCODE. The goal is to set context and then share these recommendations with the healthcare community to help mitigate common barriers and facilitate the adoption of mCODE.
©2024 The MITRE Corporation. ALL RIGHTS RESERVED
Approved for public release. Distribution unlimited 23-03929-12
FHIR and mCODE in Oncology Data Interoperability and Integration
FHIR, developed by HL7® (Health Level Seven International), is an open, standardized framework for exchanging electronic healthcare information seamlessly, and in ways that allow for building best of breed digital health solutions that scale, which includes API (Application Programming Interface) capabilities. HL7 is a global leader in open healthcare data standards, and FHIR has widespread adoption and buy-in from industry and regulatory entities for ensuring seamless interoperability across diverse healthcare systems. mCODE builds on FHIR, offering a standardized way to capture and share key oncology data. mCODE data elements cover domains such as cancer diagnosis, assessment, genomics, treatment, outcomes, and patient demographics. mCODE leverages the ease of implementation inherent to FHIR standards, resulting in simpler integration and data sharing for coordinated cancer patient care. Integrating mCODE with the broader FHIR ecosystem unlocks the potential for real-time, actionable insights that span rapidly evolving domains such as health equity, value-based care, and consumer patient access, further enhancing the quality and personalization of cancer treatment.
What mCODE Can Do for You
When you decide to utilize the mCODE information model in your clinical applications, you are positioning yourself for semantic data representation to be used in a variety of use cases. Examples of mCODE applications have been spearheaded by the CodeX™ HL7 FHIR Accelerator and others. CodeX is a community singularly focused on advancing clinical specialty FHIR standards so that patients can have the care and research journeys they deserve and should expect. CodeX convenes diverse stakeholders in outcome-focused use case pilots to advance impact and adoption, with pilot initiatives that have leveraged mCODE to tackle Cancer Registry Reporting, Clinical Trial Matching, Prior Authorization for Oncology, and more.
Beyond CodeX pilots, organizations such as Ontada/McKesson have leveraged mCODE in their business for use cases focused on real-world data (RWD) evidence-based research and on value-based contract data exchange like the Enhancing Oncology Model (EOM) under the Centers for Medicare & Medicaid Services. Mayo Clinic successfully piloted mCODE to capture structured cancer data in routine patient care. Oncoclinicas, the largest private cancer care network in Latin America, adopted mCODE and subsequently, by being able to aggregate data across its patients at previously unprecedented scale, was able to drive population insights such as evaluating outcomes for selected cohorts of metastatic breast cancer patients. These efforts are testaments to the value that mCODE adds for patient care coordination and research by supporting transactional health data exchange.
Each organization will have its own business drivers and the importance of knowing your use cases cannot be over emphasized. Taking a fit for purpose approach will ensure that the flexibility of an mCODE implementation is constrained to meet your specific needs and objectives.
What it Means to Implement mCODE
Implementing or adopting mCODE means having the ability to capture the required data elements and represent them using the appropriate values from the constrained value sets in the mCODE FHIR Implementation Guide (IG). Once that is available, mCODE data exchange is enabled through FHIR resources that are created as defined in the IG. The first step toward implementation is understanding the mCODE information model and the intentions for its use.
The mCODE Information Model
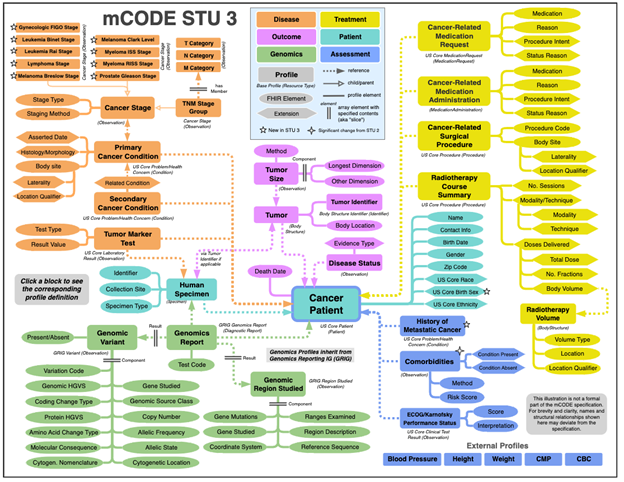
Figure 1: mCODE Standard for Trial Use (STU) 3 from https://hl7.org/fhir/us/mcode/
Figure 1 shows the scope of mCODE and the relationships of mCODE profiles from the FHIR Implementation Guide. The flexible information model is technology-agnostic and is designed for data exchange. As you dive into the IG, you will learn that mCODE does not dictate the cancer data that must be collected for all patients. If certain data is available, then that data should conform to the definition within the specification. Likewise, if you have patient data to share, and it is not defined in the specification, then it can be represented using the FHIR specification or US Core within an mCODE bundle. Because mCODE profiles can be the building blocks for new use cases, implementation guides can specify profiles that are derived from mCODE and that are expanded to include the data elements and value sets that align with the new scenarios. During your review of the guide, pay special attention to the section labeled Data Dictionary. It contains links to a flattened list of data elements in mCODE spreadsheet format. This spreadsheet tool can be used to assess potential data collection requirements, as a preliminary step, ahead of a full FHIR implementation.
Transitioning From a Model of Meaning to a Model of Use
The mCODE information model makes it possible to communicate and test the validity of the data structures. It informs a model of meaning that focuses on the semantic aspects of oncology data to ensure universal understanding. The mCODE IG also informs a model of use by describing the practical application in real-world healthcare settings.
Building the infrastructure to support the collection and use of mCODE-represented oncology data should not be done in a vacuum. An implementation covers clinical and technical considerations, and both areas should plan this work together, to ensure the use cases and requirements are understood. Here we present an approach for mCODE adoption described in Figure 2 and further detailed below.
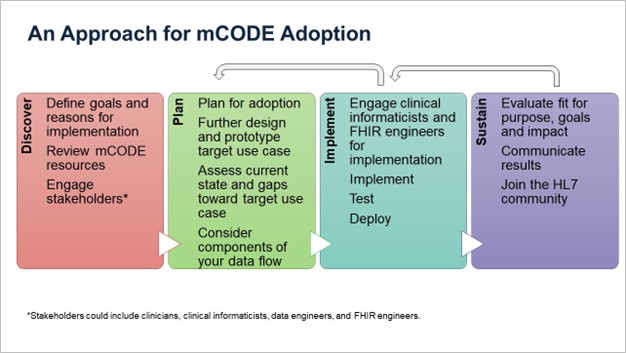
Figure 2. An Approach to mCODE Adoption
Discover
mCODE can fit many use cases within oncology, so it is important to first, define your organization’s specific goals or reasons for incorporating an mCODE model. This initial phase of mCODE adoption is critical for understanding and defining the capabilities your organization will have when mCODE is utilized. Some high-level questions to answer might be: How does mCODE align with your overall strategic plan and mission? What are the intended objectives or service levels? What are the factors for success? When defining what a successful implementation looks like, consider how you will measure the impact of mCODE on clinical outcomes, operational efficiency, and research capabilities.
It can be helpful to have a high-level concept and target use case to provide a clear picture of the fit for purpose. Being fit for purpose describes a process or service that meets the intentions of its use. Some considerations for developing your use case might include: Will you access mCODE from the clinical record or add it to a common data model, where the standardized data can be enriched with data from other systems? Will a primary use be data exchange or population health analytics and research?
Additionally, consider the resources you have available to aid in your planning. A lot of the work has been done within the information model and the FHIR IG to explain data elements, value sets, and the relationships that can be used to guide your implementation approach. Connecting with other mCODE implementors can facilitate knowledge sharing that eases adoption hurdles. Joining groups such as HL7 community (chat.fhir.org) or the CodeX HL7 FHIR Accelerator can be a bridge to other implementers that discuss how they have overcome challenges.
Most importantly, clinicians, clinical informaticists, data engineers, and FHIR engineers should develop a shared understanding of the fit for purpose(s) and plan for the best data model that meets most needs, which ultimately dictates how the data can be used.
Plan For Adoption
After identifying the intended uses, proceed to further design and create a prototype for the specific use case. Additionally, consider any organization processes, such as IT governance, data management, policies, and approvals, needed to proceed within your organization. Assess current state and evaluate gaps toward the target use case to understand where and how the mCODE data will be collected.
Consider components of your data flow, including data elements, data capture, clinical workflow, data storage, and data exchange. The clinical environment will most likely inform the best approach to implementing the ability to capture mCODE data. The goal is to be able to record the minimum necessary data elements that meet your needs. Some options are (1) capture information in structured clinical notes with data standards linked behind the scenes, (2) require direct entry of mCODE representative data by the clinicians utilizing data forms, or (3) entering free text information and utilizing some combination of natural language processing and/or large language models to interpret and abstract the data relevant to mCODE.
It will be important to understand how these requirements impact current clinical workflows. Likewise, it is important to ensure clinicians have proper training and the implementation does not introduce additional burden on their processes. Clinicians need to understand the contextual relevance of the data they enter with the aligned data standard so they can accurately capture a patient’s information.
Additionally, consider how the mCODE implementation will utilize or change your current data storage and the configurations in place for sending and receiving systems. The data-at-rest model may vary from FHIR. While storing data in native FHIR offers advantages, the way you choose to implement mCODE should be guided by specific use cases and alignment to your needs.
If you intend to utilize FHIR for the exchange of mCODE resources, determine the best representation for related data that makes FHIR resource creation/interpretation easier. Building the capability to exchange oncology data with FHIR and mCODE will position your organization for low level effort interfaces when receiving or sending patient data to other providers.
Making decisions about the classifications and summarization of the underlying data will be more direct and less burdensome with the use of a terminology/ontology system. That infrastructure will ease the interpretation of the intentional value sets utilized in the mCODE FHIR IG by programmatically identifying the descendent codes that qualify. It will also aid the summarization or classification of the mCODE data types that you may want to use when working with the data. Future proof your implementation by avoiding situations where you must pre-program or hard-code relationships to meet your needs.
Implement
After the planning stage, you are ready to begin implementation, where additional coding and configuration, customization, and integration of your mCODE solution occurs. Continue engaging clinical informaticists and FHIR engineers for implementation. Run end-to-end testing to ensure your solution is ready and scalable to the production environment. Review everything that your mCODE solution affects such as data capture, clinical workflow, and data exchange. This stage is a good opportunity to test if your mCODE solution continues to meet the goals for implementation, the use case requirements, and the needs of stakeholders. When testing is complete, you are ready to deploy and move into production.
Due to the flexibility of an mCODE and FHIR implementation, an important check point during the process is to confirm that the data is represented in the expected manner as outlined in the use cases. Sending and receiving systems involved in the exchange may implement for their own use cases, which could result in variations. One approach is to test that queries can be written that return the data in a way that meets the requirements of the implementation.
Sustain
Post-implementation sustainment means utilizing a cyclical process that evaluates the implementation on three aspects: 1) fit for purpose, 2) adoption goals, and 3) impact at your organization. Engage users of the data for feedback on the utility of mCODE in comparison to the original use cases. Evaluate the success factors defined previously in the Discover phase.
As mentioned, the HL7 community drives the healthcare data standards development process through its workgroups. Additionally, ASCO hosts the mCODE Technical Review Group (TRG), which governs and provides recommendations on updates to the data standard, including additions, subtractions, and mapping changes. Acknowledge that your organization has its own business drivers and requirements and get involved with HL7 workgroups and the mCODE community to provide valuable feedback and insight on future improvements for mCODE.
As the mCODE specification changes or new use cases are introduced, it’s important to review those changes and determine what they mean for your implementation. Each mCODE version is published with release notes that outline the latest changes. The data dictionary differential section of the IG highlights data level changes. Breaking changes will be communicated during the FHIR IG balloting process, and the balloting process presents an opportunity to share the impact these changes have on production systems. Being disconnected from changes put you at risk for falling out of conformance and could result in the accumulation of technical debt.
Ontada/McKesson’s Experience: Insights into mCODE adoption
Recognizing that organizations may not be starting from ground zero when utilizing this implementation approach, we are able to share retrospective thoughts from Ontada/McKesson on their adoption of mCODE.
As an organization that extends the mCODE implementation for both RWD research and quality measure reporting scenarios, Ontada has noted different coding requirements across these scenarios. For instance, although the mCODE implementation guide permits Cancer Condition to be coded using either SNOMED-CT or ICD-10-CM codes, the EOM submission scenario limits the code set to ICD-10-CM codes. For implementers, this implies that a medical code conversion function is necessary to address varying requirements, even if mCODE is a common data model.
Ontada also advises creating an mCODE implementation that includes the ability to apply use case specific IG constraints within FHIR profiles and bundles. For instance, the EOM IG necessitates limiting content within the Tumor Mark Test profile. Tests that fall outside this specified list may lead to submission rejections. Incorporating some type of table-driven configuration into the framework will remove the necessity for additional work or customized coding.
Overall, the mCODE implementation guide serves as an asset illustrating the logical layer of the data modeling effort. The mCODE TRG continues to enhance mCODE with version updates to reflect the evolving patterns in oncology care, such as advancements in diagnostics and therapeutical interventions. It is crucial to keep in mind that mCODE version updates can introduce changes that are not backward compatible in Ontada’s implementation. For example, the previous design of comorbidities based on the Elixhauser framework has been significantly revised. In the latest version, users are permitted to label any condition as a comorbidity, which leads to incompatibility with the formerly employed value sets, extension, code systems, and profile related to Elixhauser comorbidities.
It is essential for implementation organizations to actively participate in the mCODE TRG process, but it's equally crucial to plan for continuous efforts to assess and amend the data repository models as changes arise. Implementation organizations should balance the advantage of utilizing TRG’s advanced scientific knowledge with the effort required to adapt to the evolving data models.
Although the complexity is significant, the advantages and benefits derived from implementing mCODE as the company's universal data model surpass the expenses or risks associated with developing and maintaining a proprietary data model.
Ontada/McKesson’s additional ongoing work focuses on evaluating the suitability of mCODE for observational research. The outcomes of that exercise will be shared in a future publication.
Looking Forward
The mCODE data standard has achieved broad spectrum appeal and adoption over the last few years. Several recent federal initiatives are driving the adoption of mCODE to meet that need. The Assistant Secretary for Technology Policy (ASTP), in collaboration with the National Cancer Institute (NCI), is defining a US Core Data Interoperability (USCDI) oncology domain that will address a set of USCDI+ Cancer use cases utilizing mCODE. Initial prioritized use cases include cancer trial matching, cancer registry reporting, and immune-related adverse event reporting. Further refinement of those use cases is actively underway.
The Center for Medicare and Medicaid Innovation (CMMI) developed the Enhancing Oncology Model (EOM) for reimbursement, designed to improve the quality of care for patients at a lower cost by providing payment incentives that encourage accountability by oncology practices. The high-tech data submission process utilizes the mCODE data elements and FHIR defined resources within the specification. Additionally, ASTP published a proposed rule in August 2024 that would leverage mCODE for representation of cancer data elements for public health reporting by the start of 2028; this rule is known as HTI-2 (Health Data, Technology, and Interoperability: Patient Engagement, Information Sharing, and Public Health Interoperability).
Federal engagement has propelled further momentum in industry as well. As part of the White House Cancer Moonshot, vendors have committed to adopt the mCODE data elements leveraged in the EOM program in March 2024; the vendors included Epic; Oracle; Ontada, a McKesson business; Meditech; Flatiron; and ThymeCare.
Conclusion
The adoption and implementation of mCODE, an open data exchange standard based on FHIR, is pivotal for revolutionizing oncology data interoperability and integration. By standardizing cancer data elements, mCODE facilitates seamless data sharing and enhances both patient care coordination and research capabilities. The collaborative development and iterative refinement of mCODE, driven by the healthcare community, underscores its robust foundation and growing acceptance. Through implementation-focused use case pilots fostered by the CodeX HL7 FHIR Accelerator and beyond, diverse stakeholders and driving progress in use cases that is real-world stress tested for broad applications across research, public health, and care coordination and management.
Implementing mCODE involves understanding its information model, aligning it with specific use cases, and ensuring that clinical and technical teams work in unison to achieve a fit for purpose approach. This strategic alignment not only simplifies data exchange but also positions organizations to leverage real-world evidence for improved patient outcomes.
As federal initiatives and incentives, such as those from the ONC and CMMI, further propel the adoption of mCODE, it is important for implementers to share their real-world learnings with policymakers and the broader digital health community. The experience of Ontada/McKesson underscores the critical role that implementers play in actively engaging with the mCODE and FHIR communities, as well as with regulators, to drive the evolution of oncology data standards. By sharing real-world experiences, implementers help develop best practices that harmonize mCODE’s use across healthcare settings, thus, ensuring that standards evolve in practical, scalable ways. Engaging with communities such as the CodeX HL7 FHIR Accelerator, mCODE committees, HL7 workgroups, and related efforts, fosters a cycle of continuous improvement, where lessons learned from early adopters directly inform future advancements. This helps to drive interoperability, streamline care coordination, and unlocks the full potential of oncology data for improved patient outcomes. Active participation is key to ensuring that mCODE evolves in ways that meet the needs of both current implementers and future innovators.
Adopting mCODE is more than just a technical implementation—it is a strategic decision that empowers healthcare organizations to unlock the full potential of structured cancer data. As more organizations adopt and contribute to the refinement of mCODE, the value of shared, standardized oncology data grows, driving forward innovations in cancer treatment and research. The widespread adoption of mCODE will be a cornerstone of cancer care’s digital health transformation, which enables healthcare systems to deliver more personalized, data-driven care and ultimately improved patient outcomes on a global scale.
Contributors
MITRE:
- Miranda Chan
- Su Chen
- Karl Naden
- Gail Shenk
- May Terry
About MITRE
MITRE’s mission-driven teams are dedicated to solving problems for a safer world. Through our public-private partnerships and federally funded R&D centers, we work across government and in partnership with industry to tackle challenges to the safety, stability, and well-being of our nation.
Ontada/McKesson:
- Lisa Deister
- Wanmei Ou
About Ontada®
Ontada is an oncology technology and insights business dedicated to transforming the fight against cancer. Part of McKesson Corporation, Ontada was founded on the core belief that precise insights – delivered exactly at the point of need – can save more patients’ lives. We connect the full patient journey by combining technologies used by The US Oncology Network and other community oncology providers with real-world data and research relied on by all top 15 global life sciences companies. Our work helps accelerate innovation and powers the future of cancer care. For more information, visit ontada.com.
Published on
January 15, 2025
Related

Health Information Exchange
White Papers


